Metrics tell you something is wrong. Root cause analysis tells you why. This is the fundamental difference between monitoring and debugging — and most deep-learning teams are stuck in monitoring mode.
When a model underperforms, the standard response is to collect more data, adjust hyperparameters, or try a different architecture. These are reasonable guesses. But they're still guesses.
The systematic approach to deep-learning debugging:
1. Locate the failure, not just the metric
Before you touch the model or the data, you need to know which samples the model is failing on and what they have in common.
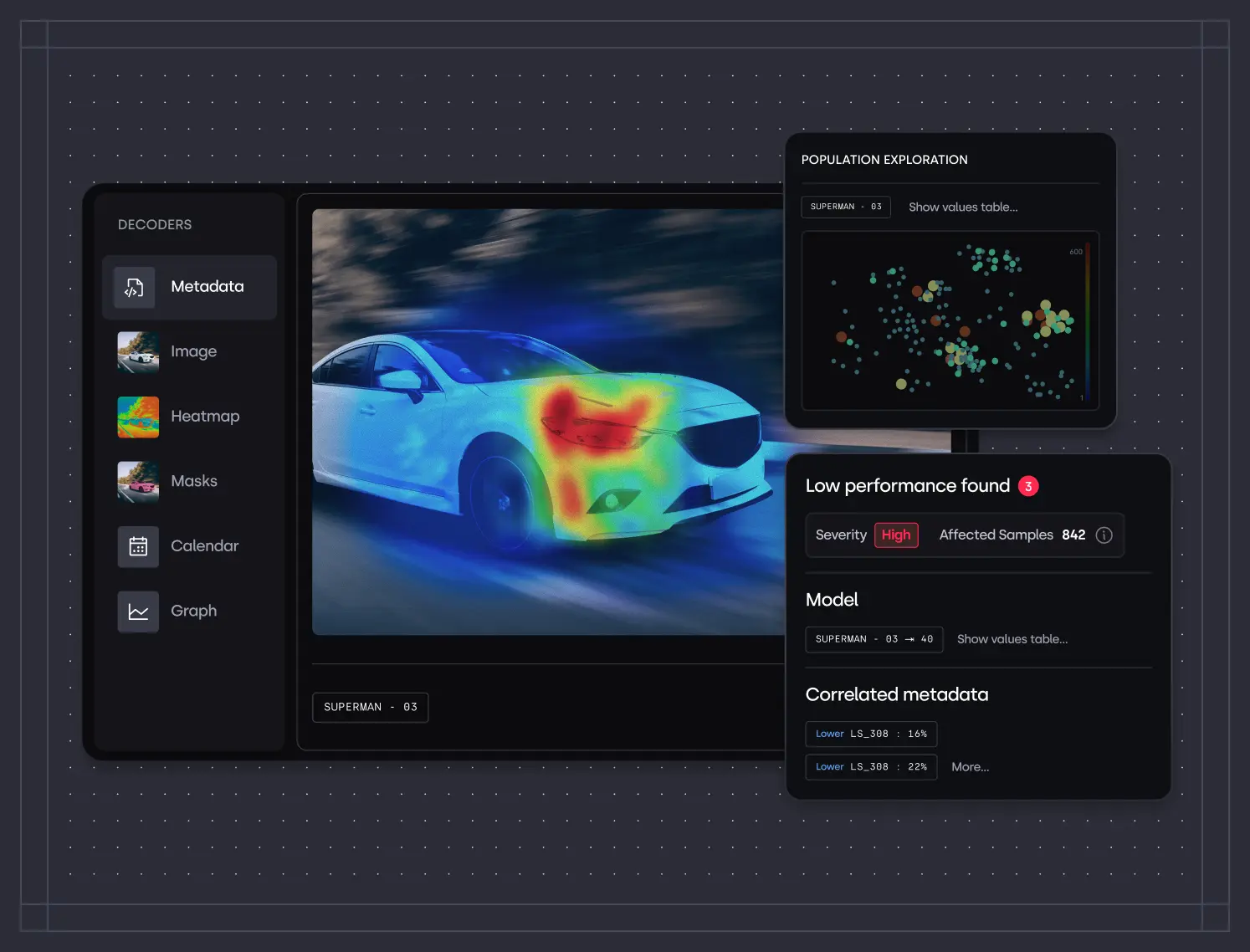
Clustering techniques, representation learning, and attention-based analysis can map your model's failures to specific data populations. Are failures concentrated in a particular lighting condition? A specific object class? A narrow range of input sizes?
2. Trace failures to their cause
Once you know where failures are concentrated, you can ask why. Is this a training data gap — are these scenarios underrepresented? Is it a model capacity issue — does the model lack the features to handle these cases? Is it a labelling quality issue — are the training labels for this population incorrect?
3. Apply the targeted fix
With root cause in hand, the fix becomes obvious: - Data gap → targeted collection and labelling - Model capacity → architecture adjustment or loss modification - Label quality → relabelling specific population
4. Validate and monitor
After the fix, validate that performance improved on the specific failure population without regressing on others. Then set up monitoring to catch similar failures early.
The teams that ship reliable models fastest aren't the ones with the most data. They're the ones who spend the least time guessing.